365 Days of Stories – Day 7: From Learning to Building – The Start of Product Development
With the core foundation in place, it was time for product development.
Since this was a high-volume system, I knew scalability had to be a key focus from Day 1.
So, I followed a structured approach:
1️⃣ Requirement Documentation 2️⃣ Design (UML – Class Diagram & ERD – Database Design) 3️⃣ Coding
This wasn’t just another CRUD-based application—it involved complex design decisions that had to be done right from the start.
Instead of worrying about design issues and ride-matching complexities, I decided to take it step by step.
Step 1: Documenting the Requirements I documented product requirements, focusing on features and system behavior without worrying about feasibility.
🔹 Clarity increased as I documented features. 🔹 Key system challenges became visible. 🔹 Design decisions became more structured.
This process took just 2 days, but the impact was huge.
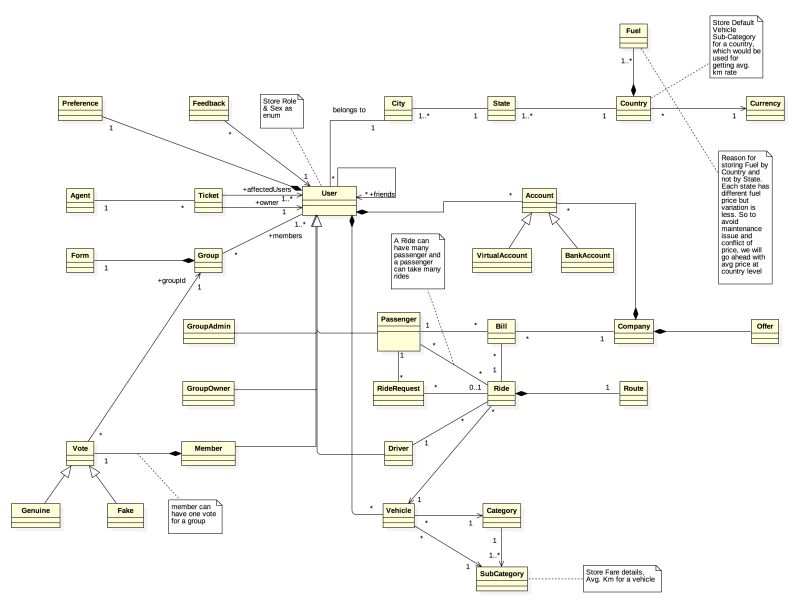
Step 2: Designing the System Class Diagram – Building the Domain Model I created a class diagram, focusing on entity relationships to visualize the architecture.
Database Design – The Core of the System At NCST, I had worked on a Railway Reservation System as a project. My partner, Parwez Mohammad, was my biggest support system.
🔹 He grasped new languages fast, then taught me. 🔹 We worked in sync—he coded first while I shadowed, then he handed over coding to me.
💡 This was pair programming, a technique I later discovered was a big part of Thoughtworks development approach.
🔹 NCST forced us to deliver every project in groups, making collaboration key.
One core learning from NCST:
⚡ If ERD is perfect, coding is easy. If ERD is messy, handling every scenario becomes complex.
So, I spent a lot of time ensuring my ERD was solid, as my system would handle billions of ride data points.
Step 3: Choosing the Right Tech Stack I took a minimalistic approach, selecting only essential technologies to keep the learning curve small.
One of the biggest decisions was where to store ride data.
A ride in my system is a collection of GPS points at 5-50 meter intervals.
For example, a 10 km ride would generate ~200 data points.
🔹 If my system had 1M rides/day, it would store 1B+ points in just 5 days!
To handle this: ✔ Relational DB for structured data. ✔ Horizontally scalable NoSQL DB for ride points. ✔ Geospatial Indexing for efficient ride matching.
After evaluating multiple databases, I chose MongoDB (cloud version) for its: ✔ Horizontal scaling support ✔ Built-in spherical indexing for location-based searches
Next Up: Cracking the Core Logic – Ride Matching Algorithm With design decisions locked, it was time to tackle the real challenge— 🚀 How to match ride partners?
Have You Ever Built a Scalable System from Scratch? Would love to hear your thoughts on designing for scale and handling large datasets!
hashtag#365DaysOfStories hashtag#Day7 hashtag#StartupJourney hashtag#PersonalBrand hashtag#ElevateIdea